Google Drive is a file storage and synchronization service developed by Google. It enables file management, collaboration, and so on. You can connect a Google Drive target to the data flow, and load the ETL into the Google Drive as a delimited Text file.
Add a Google Drive Target node
To load the Data Flow (ETL) into a Google Drive target, you need to add the Google Drive node from the Targets panel onto the canvas.
From the Elements section of the Data Flow page:
- Select Targets.
- Drag the Google Drive node onto the canvas.
- Connect the Google Drive node to the Table or Tables on the Data Flow.
- Select the target Google Drive node on the canvas.
When the node is selected on the canvas, the Properties panel opens to the right-hand side. You will configure the target in this panel.
Configure the Google Drive Target
Basic Properties
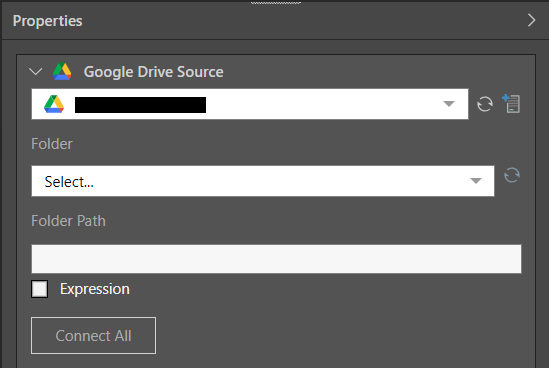
From the Properties panel:
- Select the required target from the server list drop-down.
- Choose the required folder and provide the path to the folder.
- Next, click Connect All to connect the target to the data flow.
The path can be a static value pasted in the Folder Path field, or you can create a dynamic PQL expression in the PQL editor by selecting the Expression checkbox and opening the PQL Editor using the PQL icon.
File Properties
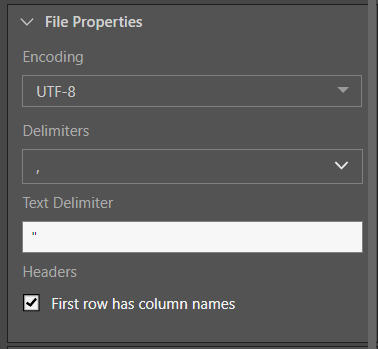
From the File Properties window, set the properties of the Google Drive file output:
- Encoding: provide the character encoding set for the new database file.
- Delimiters: select or enter the value delimiter.
- Text Delimiter: enter the text delimiter.
- Headers: if the file's first row is made up of column names, enable 'First row has column names'.
- Click here to learn more about Text file properties.
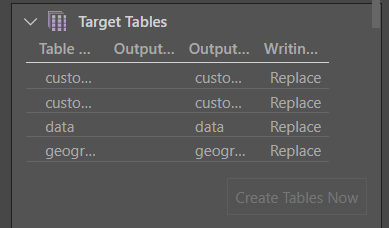
Target Tables
From the Target Tables window, you can rename the table outputs and change the writing type.
- Click here to learn more about target tables.
Description
Expand the Description window to add a description or notes to the node. The description is visible only from the Properties panel of the node, and does not produce any outputs. This is a useful way to document the ETL pipeline for yourself and other users.
Run the ETL
As there is no database or in-memory destination, the Data Model and Security stages are not relevant. Skip these steps and simply run the ETL from the Data Flow.